Notebooks associés
- algorithme de recherche de plus proches voisins KNN: algKnn
- algorithme de recommandation : algorithme de recommandation.md
- arbres de décision : graphes_mini_prog.md
Intelligence artificielle (IA)
L’intelligence artificielle désigne des algorithmes plus ou moins évolués qui traitent des problèmes dont la résolution fait appel à l’intelligence humaine. Ils imitent des actions humaines.
Le comportement de l’algorithme évolue au cours du temps, en fonction des données qui lui sont fournies.
Aujourd’hui, ce sont les chatbots qui illustrent le mieux cette notion d’IA. Il existe ainsi:
- les chatbots basés sur des règles: (plus simples que l’ IA):
- suivent un ensemble de règles pré définies
- servent pour un flux de discussion prédeterminé
- doivent être configurés à chaque mise à jour
- les chatbots basés sur IA:
- comprennent le contexte, interprètent l’intention d’une conversation
- peuvent apprendre des interactions
- peuvent traiter des projets plus complexes
Les chatbots issus de l’IA conversationnelle: sont des technologies grâce auxquelles les logiciels peuvent converser avec des personnes en utilisant le langage naturel.
- Voir article sur le test de Turing
- Voir aussi l’article de Thierry Viéville, illustré de videos de D. Louapre chatgpt: voulez vous comprendre ce que c’est?
- Voir en particulier la video sur le machine learning et les reseaux de neurone, après 10min: Lien vers la video
Analyse de données et machine learning
une définition
imaginons que vous vouliez créer une IA qui vous donne le prix d’un appartement à partir de sa superficie.
Dans les années 1950, vous auriez fait un programme du type « si la superficie est inférieure à 20m², le prix vaut 60 000€, si elle est entre 20m² et 30m², le prix vaut 80 000€, etc… », ou peut-être « prix = superficie*3 000 ».
Mais ce type de problème ne peut pas être résolu de manière satisfaisante avec de telles approximations: il vaudrait mieux constater le prix de plusieurs appartements, issus de différents quartiers, de qualités différentes (des variables, comme la superficie, l’exposition, le vis-à-vis…). On pourra alors estimer le prix d’un nouvel appartement non-référencé selon ses caractéristiques (ses variables).
C’est ce type de démarche qui est attendu lorsque l’on fait du machine learning, ou de l’apprentissage autonome. C’est un sous-domaine de l’intelligence artificielle. En pratique, le programme va analyser une partie des données pour rechercher les corrélations ou les similitudes entre les objets. Il va alors former des classes, ou établir des relations, ou des probabilités.
Le machine learning est un domaine large, qui comprend de très nombreux algorithmes. Parmi les plus célèbres, on retrouve :
- Les régressions (linéaires, multivariées, polynomiales, régularisées, logistiques…) : ce sont des courbes qui approximent les données
- L’algorithme de Naïve Bayes : l’algorithme donne la probabilité de la prédiction, sachant les événements antérieurs. Par exemple, quel est le prix le plus probable sachant que l’appartement X fait 43.7m², qu’il occupe une position privilégiée dans le quartier Montmartre, en rez de jardin, sans parking, sans vis-à-vis… voir à ce sujet l’excellent article sur le blog sciencesetonnantes de David Louapre : probabilités conditionnelles (Bayes)
- Le clustering : toujours grâce aux mathématiques, on va grouper les données en paquets de manière à ce que dans chaque paquet les données soient les plus proches possibles les unes des autres. C’est utilisé notamment pour des recommandations (films, articles achetés…)
- Les arbres de décision : en répondant à un certain nombre de questions et en suivant les branches de l’arbre qui portent ces réponses, on arrive à un résultat (avec un score de probabilité)
- Ainsi que des algorithmes plus perfectionnés reposant sur plusieurs techniques de statistiques
Les domaines professionnels
Tous les champs professionnels, du moment où il y a des données qui sont collectées : dans l’entreprise, le commerce, dans la recherche, …
Ces données sont collectés à partir d’objets connectés, à partir de l’activité des internautes sur les sites de e-commerce (marketing digital), des statistiques d’utilisation de produits, de véhicules, de bâtiments, voire des données collectées suite à des évènements naturels, biologiques, etc.
Ces données peuvent servir les domaines de la santé (suivi de la propagation d’épidémies, aide au diagnostic,… des transports (analyse de flux,), de l’environnement (prévisions météorologiques, contrôle de la pollution), mais aussi dans l’analyse de la clientèle dans l’industrie et le commerce.
En se basant sur des informations passées, les techniciens spécialisés dans l’observation des grosses données (big datas) peuvent ainsi faire des prévisions dans chacun de ces domaines. Ou prendre des décisions en fonction des variables.
Le principe : on récupère les données, on les nettoie, on les explore, puis on utilise nos algorithmes pour créer de l’intelligence (artificielle) qui aide à la prévision/décision. Ces algorithmes sont basés sur des outils statistiques. La machine qui execute un tel algorithme est capable d’apprendre de manière autonome, dans une séquence où les données collectées servent à établir un modèle. La machine améliore son modèle grâce à un score associé à l’exploitation des données. Puis elle utilise ce modèle lorsque le score est optimal pour résoudre une série de problèmes.
Exemples :
- biologie :
- Expressions de gènes (transcriptome, relation gène / protéines)
- Paléontologie et évolutions
- médecine : Pharmacovigilance
- chimie :
- Prédiction de la toxicité des molécules, mécanismes réactionnels
- physique :
- Astronomie : répertoire des corps célestes
- Expériences en physique des particules (LHC au CERN)
- sciences environnementales :
- Comprendre les milieux naturels, l’impact de l’homme, etc
- sciences sociales :
- Analyse d’opinions sur le Web
- Analyse des recherches sur le Web : Google Trends
Vocabulaire
-
dataset : jeu de données. Ce jeu de données peut en contenir un petit nombre ou un très grand nombre de données (big data). Ces données peuvent être discretes (qualitatives) ou continues (valeurs numériques).
-
big data : données massives. Des données qui sont collectées en continu et en grande quantité. Cela constitue un flux si important qu’il est obligatoire d’utiliser des techniques de traitement spécifiques au domaine du machine learning pour pouvoir les exploiter. On décrit le big data à l’aide des 3V : Volume, Velocity (peu de temps pour traiter les données), Variety (des données diverses)
-
Une classe : c’est un champ particulier à valeurs discrètes.
-
Différents type de programmes en analyse de données : programme de classification, de prédiction, d’estimation, d’association.
-
La classification : consiste à examiner les caractéristiques d’un objet et lui attribuer une classe :
- attribuer ou non un prêt à un client
- établir un diagnostice
- placer une roche, une espèce végétale, animale… dans une catégorie
-
Prédiction : consiste à prédire la valeur future d’un attribut en fonction d’autres attributs. Deux exemples :
- Regression : estimer le chiffre d’affaire d’un nouveau magasin, estimer le prix du loyer en fonction de la surface de l’habitation
- classification supervisée : estimer la probabilité qu’un client pratique un sport donné à partir de l’historique de ses achats
-
Modèles prédictifs : utilisent les données avec des résultats connus pour développer des modèles permettant de prédire les valeurs d’autres données.
-
Modèle descriptif : propose des descriptions des données pour aider à la prise de décision. C’est un modèle surtout utilisé en segmentation et association.
-
Apprentissage supervisé : les données à analyser comprennent à la fois des données d’entrée et de sortie. On connait la classe des objets, et on cherche à prévoir l’appartenance à une de ces classes pour tout nouvel objet.
Lorsque l’on cherche à comprendre ou définir une relation entre les données, on peut pratiquer une association : qui consiste à déterminer les attributs qui sont corrélés :
C’est ce que l’on réalise lorsque l’on fait l’analyse d’un panier de courses au supermarché (ou sur un site d’e-commerce) : poisson et vin blanc sont deux articles qui vont souvent occuper ensembles le panier.
- Apprentissage non supervisé : Seules les entrées sont fournies. Par exemple : identifier des familles de fournisseurs et de clients pour faire un mailing ciblé
Une technique pratiquée en apprentissage non supervisé : la Segmentation : consiste à former des groupes homogène à l’intérieur d’une population (des clusters).
Les étapes du traitement de données
- Aggréger ces données dans un data lake.
- Nettoyer les données. C’est à dire s’assurer qu’elles sont consistantes, sans valeurs aberrantes ni manquantes, et mises dans le bon format.
- Explorez les données. Cette étape doit permettre de mieux comprendre les différents comportements et de bien saisir le phénomène sous-jacent. On cherche:
- soit à réaliser une classification, par exemple sous forme arborescente. C’est ce que l’on cherche à réaliser lorsque l’on peut discriminer la population à trier à partir de critères qualitatifs. L’idée est alors de trouver les bonnes clés de tri, qui vont partager la population.
- soit à chercher une corrélation entre grandeurs, si celle-ci sont numériques. Chaque donnée observée est l’expression d’une variable aléatoire générée par une distribution de probabilité. On cherche alors à énoncer une conclusion du type : “suite à l’exploration, il y a clairement une relation entre X et Y, ces 2 grandeurs semblent liées par une relation de regression linéaire (ou non linéaire) du type Y = a*X + b (ou autre)”.
- Modéliser les données.
- Dans le premier cas, à partir de valeurs dites discrètes (des catégories), on devra réaliser une segmentation des objets en entrée en différentes catégories. La prédiction réalisée à partir d’une nouvelle entrée donne en sortie une liste de labels possibles.
- Dans le deuxième cas, il s’agira d’un traitement statistique des données.
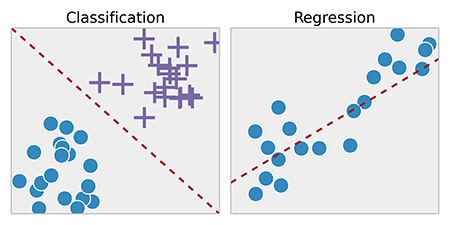
illutration de la différence entre classification et regression linéaire
- Déployer le modèle. Une fois le modèle établi, on va encore le vérifier et l’ajuster à partir de certaines des données : il faudra donc prévoir une séparation initiale de ces données : certaines des données servent à générer le modèle (le training set). Les autres sont celles qui vont permettre de valider (tester) ou améliorer si besoin le modèle (le testing set).
- Prévoir la catégorie ou faire de la prédiction à partir des nouvelles données.
Le machine learning est l’apprentissage d’un modèle statistique par la machine grâce à des données d’entraînement. Un problème de machine learning comporte parmi les étapes une mesure des performances. S’il améliore les performances sur cette tâche lorsqu’on lui fournit les données d’entraînement, on dit alors qu’il apprend.
Exemples
On pourra retrouver ces exemples plus en détail dans leur page originale : https://openclassrooms.com/fr/courses/4011851-initiez-vous-au-machine-learning/5868296-transformez-des-besoins-metiers-en-problemes-de-machine-learning
Comment recommander un produit à un client
mots clés : Données discretes, règles d’association, apprentissage non supervisé.
La recommandation est une problématique qui revient très souvent dans l’ananlyse de données pour le marketing électronique. La recommandation se base sur des similarités entre utilisateurs, ou bien des similarités entre produits. Ce filtrage collaboratif repose sur l’adage : Si deux personnes ont aimé des contenus identiques par le passé, elles ont une probabilité élevée d’aimer les mêmes choses dans le futur.
Sur l’image ci-dessous, on regarde par exemple ce qu’ont voté les utilisateurs similaires, c’est-à-dire ceux qui ont déjà voté la même chose sur d’autres produits (surlignés en vert). On peut alors prédire ce qu’aurait voté notre utilisateur sur le produit cherché, et ne proposer que les produits sur lesquels il aurait mis un pouce vert.
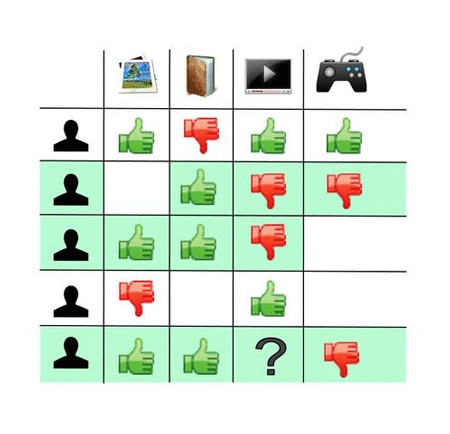
Les utilisateurs similaires (en vert) n'ont pas aimé le produit que notre utilisateur n'a pas encore noté. L'algorithme aura donc tendance à prédire une mauvaise note et à ne pas recommander le produit ici
Les utilisateurs similaires (en vert) n’ont pas aimé le produit que notre utilisateur n’a pas encore noté. L’algorithme aura donc tendance à prédire une mauvaise note et à ne pas recommander le produit ici.
En pratique : On peut voir la liste des profils utilisateurs comme une matrice. L’objectif d’un algorithme de recommandation est de remplir les cases vides de cette matrice. Quel serait le score de Gregory (dernière ligne du tableau) pour l’article “ordinateur portable”, marqué avec un
?. Il faudra établir une correspondance entre les objets et les profils.
Il existe alors plusieurs méthodes d’association :
- l’association basée sur les clients (voir exemple ci-dessus)
On pourrait par exemple, calculer un coefficient de similitude entre Gregory et les autres usagers pour tous les articles renseignés, puis établir une liste triée.
- l’association basée sur les objets (l’exemple dit du panier de la ménagère)

une liste d'achats
Cette fois on ne s’interesse plus au profil du client, mais on cherche une règle d’occurence entre les objets. Pour trouver les associations entre 2 produits, on construit le tableau de co-occurrence montrant combien de fois 2 produits ont été achetés ensemble.

tableau de co-occurence
Ici : le produit A apparaît dans 80% des achats, le produit C n’apparaît jamais en même temps que le produit E, les produits A et D apparaissent simultanément dans 40% des achats. Ces observations peuvent suggérer une règle de la forme : « Si un client achète le produit A ALORS il achète le produit D ».
On cherche alors à générer des règles du type : si A alors D avec, pour chacune, un pourcentage de confiance. Par exemple, cette règle apparaissant ici apparaissant dans 40% des achats, on considère que le pourcentage de confiance est égal à 40%.
Le clustering
mots clés : Données continues, apprentissage non supervisé, algorithme des k-plus proches voisins
Le clustering désigne les méthodes de regroupement automatique de données qui se ressemblent le plus en un ensemble de “nuages”, appelés clusters. On cherche repérer, et mesurer la similarité entre les différentes données. Par exemple, les points sur le graphe ci-dessous peuvent être considérés comme similaires s’ils sont proches en termes de distance.
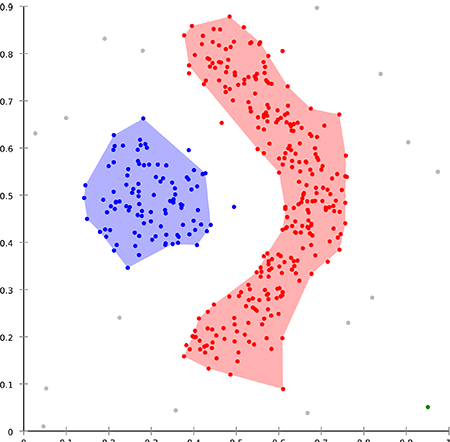
L'objectif du clustering est de retrouver les différents clusters de données, c'est-à-dire de regrouper les données similaires entre elles
On pourra étudier cet exemple en détail avec la page Python algo KNN de ce même site.
utilisation d’un arbre de décision
mots clés : Données discretes ou continues, classes, attributs, segmentation.
- A partir dʼun ensemble de valeurs d’attributs, il sʼagit de prédire la valeur d’un autre attribut (variable cible).
- Un arbre est équivalent à un ensemble de règles de décision.
L’idée est de bien choisir l’(les) attribut(s) discriminant(s). L’arbre est construit en découpant successivement les données en fonction des variables prédictives. L’algorithme qui realise ce travail utilise des grandeurs statistiques pour mesurer la qualité de la segmentation.
Une fois l’arbre construit, pour prédire la classe (la variable cible) d’une nouvelle entrée (une instance), il faut parcourir l’arbre depuis la racine jusqu’à la feuille.
Exemple 1 : Il s’agit de prédire si, selon la météo(ciel, temp., humidité et vent), on va aller jouer au tennis.
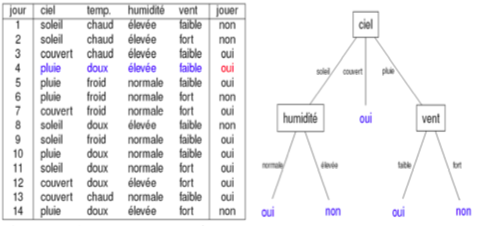
construction d'un arbre de décision
Chaque chemin, depuis la racine jusqu’à une feuille est une règle de décision. Par exemple ici :
si ('ciel' == 'soleil') et ('temp.' == 'doux') et ('humidité' = 'élevée') et ('vent' == 'faible' ) alors (classe = 'oui')
Exemple 2 : Arbres de classification et régression
On peut aussi réaliser ce type de segmentation avec des attributs à valeurs continues. On cherche alors à regrouper déterminer des clusters à partir du regroupement des classes.
L’exemple suivant montre la répartition des éléments dans un diagramme (x1;x2). Une fois ce premier travail réalisé, on pourra construire un arbre de classification à partir des tests sur x1 et x2. Par exemple
si x2<0.42 alors classe = 'Vert'
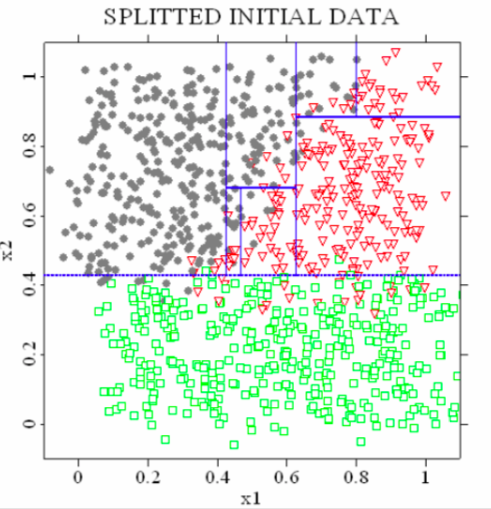
résultat obtenu par recherche de clusters sur un jeu de données bidimensionnelles à trois classes
Liens
documents utilisés pour la redaction de la page
- s’initier au machine learning https://openclassrooms.com/fr/courses/4011851-initiez-vous-au-machine-learning/4020611-identifiez-les-differents-types-dapprentissage-automatiques
- Méthodes de fouilles : http://www.lsis.org/espinasseb/Supports/DWDM/10-MethodesFouille-4p.pdf
- La règlementation sur les algorithmes d’IA: Faut-il interdire ces algorithmes dans certains secteurs: rapport du CNIL: garder la main
- Comment rendre les algorithmes responsables? Le Monde.fr internetactu
Approfondissement
-
Différence entre Intelligence Artificielle, Machine Learning et Deep Learning : http://penseeartificielle.fr/difference-intelligence-artificielle-machine-learning-deep-learning/
-
Inférence bayesienne : Les probabilités conditionnelles (Bayes) - le blog de David Louapre : https://sciencetonnante.wordpress.com/2012/10/08/les-probabilites-conditionnelles-bayes-level-1/
-
theorie sur le machine learning : https://makina-corpus.com/blog/metier/2017/initiation-au-machine-learning-avec-python-theorie
-
machine learning : utiliser SciKit https://makina-corpus.com/blog/metier/2017/initiation-au-machine-learning-avec-python-pratique
-
apprentissage statistique avec scikit-learn : https://www.math.univ-toulouse.fr/~besse/Wikistat/pdf/st-tutor3-python-scikit.pdf
