- introduction aux graphes
- cours sur les graphes. Term NSI
- algorithmes de parcours des graphes
- TP sur l’implementation en python des graphes
- TP sur les algorithmes de parcours des graphes (app en ligne)
- algorithme de Dijkstra
- Protocoles de routage
- Arbres
Graphe pondéré : Algorithme de Dijkstra
On va voir une variante, plus complexe, de l’algorithme BFS : l’algorithme de Dijkstra. Cet algorithme permettra de calculer toutes les distances entre un sommet de départ r et les autres sommets, mais cette fois ci, ce graphe est pondéré.
Pour un graphe pondéré, chaque arête (u,v) a une longueur notée l(u,v). Pour certaines applications, on parle plutôt de poids d’une arête. Jusqu’à présent nous n’avons traité que le cas particulier où l(u,v) = 1.
Comme l’algorithme précédent, celui-ci donnera la distance selon le plus court chemin.
Au départ, aucune distance n’est connue. Les distances provisoires notées distG(r,u), sont mises à l’infini : pour tout u, distG(r,u) = ∞
Le graphe suivant servira d’exemple :
exemple de graphe pondéré
La méthode employée diffère légèrement de celle du parcours en largeur. Il faudra également utiliser une liste L de sommet à parcourir. Mais cette liste est constament remise à jour (triée) en fonction des longueurs des arêtes constatées, comme on le verra plus loin.
De plus, il faudra mémoriser le sommet parent d’un sommet visité. Ce sommet parent pourra être modifié si on trouve un chemin plus court pour atteindre ce sommet depuis le sommet de départ.
algorithme
Structures de données
- un graphe G
- un tableau T comportant autant de lignes et de colonnes que le graphe comporte de sommets.
- une liste L pour établir l’ordre de visite des sommets
Algorithme
On part du sommet r :
- On colore r en rouge, preuve que l’on a (ou que l’on va…) visité-er tous ses sommets adjacents. Pour chaque sommet adjacent u: On note la distance qui sépare r de u selon la longueur de l’arête.
- On ajoute cette information (longueur r-u) au tableau T dans la ligne du sommet parent, le sommet r
- On ajoute chaque sommet u dans la liste L avec la mention de la distance à r (u, distance)
- On trie la liste L par ordre de distance à r croissante.
- On choisit comme nouveau sommet de depart v, celui qui a la plus petite distance dans le tableau T. On colore v en rouge. On retire v de la liste L
- On visite tous les sommets w voisins de v. On les ajoute dans la liste L. On indique pour distance la somme distG(r,v) + distG(v,w)
- Pour chaque voisin w du sommet v : si distG(r,w) < distG(r,v) + distG(v,w), c’est que le sommet w a déjà été visité, et que le chemin déjà trouvé est plus court que le chemin actuel. On ne fait rien. si distG(r,w) > distG(r,v) + distG(v,w), c’est que le sommet w a peut être été visité, mais que le chemin actuel est le plus court. On note alors la nouvelle valeur de la distance dans le tableau T, dans la ligne v, colonne w: distG(r,w) = distG(r,v) + distG(v,w). C’est actuellement le meilleur chemin.
- Puis, lorsque tous les voisins de v ont été visités, on revient au point 4 pour v (trier la liste L, coloration en rouge,…).
Ce qui change par rapport à l’algorithme BFS, c’est le choix du nouveau sommet à visiter lors du parcours du graphe : lorsque tous les sommets adjacents ont été visités, et que l’on a mémorisé leur distance au sommet de départ, on choisit d’explorer le sommet le plus proche du sommet de depart, celui le plus à gauche dans la liste L.
Il faut donc trier cette liste à la fin de chaque exploration.
Illustration
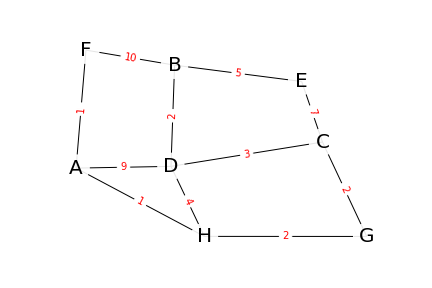
On démarre du sommet Bvoisins. Après le parcours de ses voisins, la liste L contient les sommets D,E,F classés par ordre de distance croissante :
$$L = [(D,2), (E,5), (F,10)]$$
- D est à une distance de 2
- E est à une distance de 5
- F est à une distance de 10
L = [(D,2), (E,5), (F,10)]
B:
| exploration depuis le sommet… | A | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|
| B | ∞ | ∞ | 2 | 5 | 10 | ∞ | ∞ |
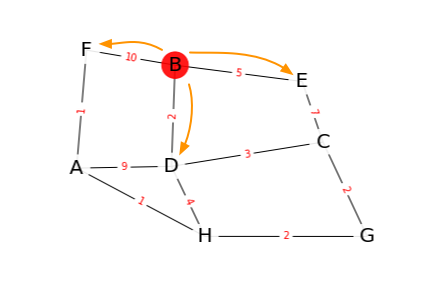
Ensuite, on passe au sommet D, le plus proche de B (le plus à gauche dans la liste) :
- C est à une distance 2+3 = 5 de B
- H est à une distance 2+4 = 6 de B
- A est à une distance 2+9 = 11 de B
On ajoute C, H et A à la liste. L = [(E,5), (F,10), (C,5), (H,6), (A,11)]
Puis on trie cette liste:
L = [(C,5), (E,5), (H,6), (F,10), (A,11)]
| exploration depuis le sommet… | A | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|
| D | 11 | 5 | ∞ | 6 |
Les valeurs pour D, E et F ne sont pas remises à jour. On ne les mentionne pas dans ce tableau.
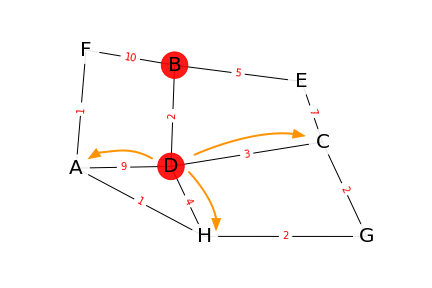
Le sommet suivant à traiter est alors le C. Ses voisins sont E, et G. L’examen du chemin vers E ne change rien : le chemin B,D,C,E a une longueur plus importante que le chemin direct B,E (12>5). Par contre, le chemin vers G offre une nouvelle distance :
- G est à une distance 5+2 = 7 de B :
| exploration depuis le sommet… | A | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|
| C | 7 |
On ajoute G à la liste et on trie:
L = [(E,5), (H,6), (G,7), (F,10), (A,11)]
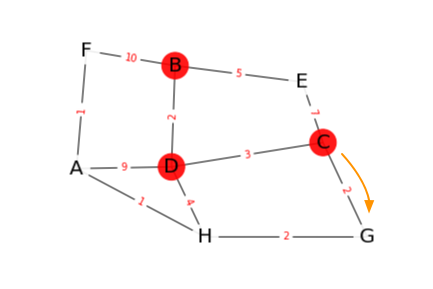
- A est à une distance 6+1 = 7 du noeud B. C’est le meilleur chemin.
- G est à une distance 6+2 = 8 du noeud B en passant par H. Cette valeur n’est pas enregistrée car il existe un chemin plus court.
| exploration depuis le sommet… | A | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|
| H | 7 |
L = [(A,7), (G,7), (F,10)]
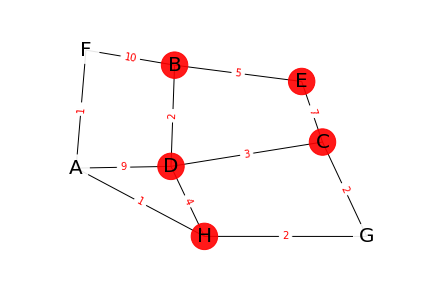
Fin de l'exploration
| exploration depuis le sommet… | A | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|
| A | 8 |
Ainsi, le plus court chemin pour faire B => F est trouvé en remontant dans les tableaux successifs:
- F est à une distance 8 de B en passant par A
- A est à une distance 7 de B en passant par H
- H est à une distance 6 de B en passant par D
- D est à une distance 2 de B
Arbre représentant ce graphe
L’arbre représentant les plus courts chemins est alors le suivant :
arbre couvrant
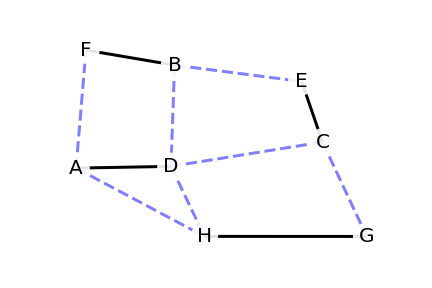
On peut le représenter avec une forme plus conventionnelle :
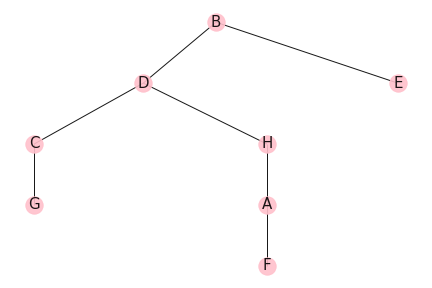
arbre de plus court chemin
