Coder une image
Une image: un tableau de pixels
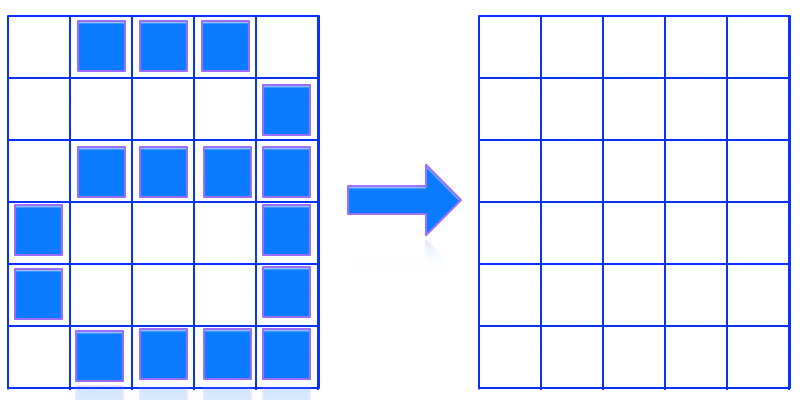
image pixelisée monochrome
Comment représenter l’image de ce symbole de manière numérique? Compléter la grille de droite avec les valeurs 0 ou 1.
L’objet mathematique correspondant est une matrice. C’est un tableau constitué de lignes et colonnes. Le caractère a sera représenté par la matrice M:
M = [[1,0,0,0,1],
[1,1,1,1,0],
[..],
[..],
[..],
[..]]
M est une liste de lignes, où chaque ligne est aussi une liste.
Construire une image numérique
On utilise des boucles simples ou imbriquées, constituées d’une seule ou plusieurs instructions pour peindre les pixels (voir activité sur le site Algorea):

pixels sur une ligne: boucle simple
faire 6 fois:
peindre en rouge
faire 6 fois:
peindre en bleu

tableau de pixels. boucles imbriquées
faire 12 fois:
faire 6 fois:
peindre bleu
peindre rouge
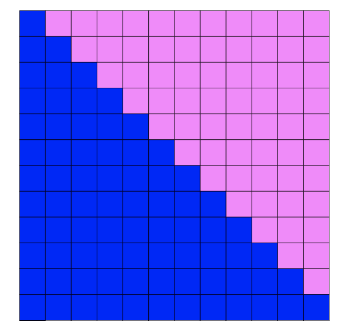
tableau de pixels. utiliser un variant de boucle
pour i variant de 0 à 11:
pour j variant de 0 à i:
peindre bleu
pour k variant de i+1 à 11:
peindre en magenta
codage de l’image dans un fichier
Les plus petits détails de l’image sont ses pixels : des petits carrés remplis chacun avec une seule couleur. Coder les pixels de l’image revient à coder les couleurs de ses pixels. Les valeurs des couleurs des pixels sont alors mises les unes à la suite des autres, et constituent ainsi le fichier image en s’ajoutant aux métadonnées.
P1
6 5
0 1 1 1 0 1
0 0 0 0 1 1
...
Grâce aux métadonnées du fichier, les informations de format (P1, P2, …) et de dimension (6 * 5), l’ordinateur va traiter cette suite de chiffres selon une matrice de valeurs:

import des données du fichier dans un programme python. Codage des couleurs en 24 bits rgb
Chaque information va coder la couleur d’un pixel (un petit carré de couleur uniforme). Une fois agrandie, l’affichage ne pourra pas proposer plus d’informations que celles contenues dans le fichier source. C’est pour cette raison que l’image apparait parfois pixelisée.

image pixelisée couleur
Le poids de cette image : pour 100 pixels sur 100 pixels (10 000 px) $$nombre\quad pixels \times 3 octets = 10000\times 3 = 30000 octets $$ Ce qui correspond à $$\tfrac{30000}{1024} = 29ko$$
Codage d’une image dans un tableau de données
On a vu en travaux pratiques, que le programme qui permet l’affichage des données en tableau utilise 2 boucles bornées, imbriquées:
# L est un tableau python 5 * 5
for j in range(5):
for i in range(5):
if L[j][i] == 1 :
display.set_pixel(i, j, 9)
On obtient alors une image de type Noir et Blanc, sur une matrice de diodes 5 * 5.
Profondeur de couleur
La représentation bitmap d’une image par une matrice de pixels ne se limite pas à des images binaires en noir (0) et blanc (1).
En modifiant la profondeur de l’image, on peut coder plus de couleurs dans un pixel
niveaux de gris
(voir image plus bas).
Par exemple, le tableau suivant représente des valeurs allant du plus foncé au plus clair:
# fichier
P2
3 2
0 50 100 150 200 255
# matrice
pix = [[0,50,100],[150,200,255]]
couleur
Le codage des couleurs utilise la synthèse additive. Voir animation sur Algorea > SNT V2 > photographie numerique > ambiance lumineuse
# fichier
P3
2 3
255 0 0 0 255 0 0 0 255 255 255 255
255 0 0 0 255 0
# matrice
pix = [
[[255,0,0],[0,255,0]],
[[0,0,255],[255,255,255]],
[[255,0,0],[0,255,0]]
]
Saurez-vous deviner le codage des couleurs sur cette image?
certains logiciels de design proposent de faire des essais de coloration. Ici, données en hex
Caractéristiques des images
Luminosité d’une image
La luminosité d’une image représente la clarté de l’image. Pour un pixel donné, on peut établir une mesure de la luminosité de la manière suivante : Soient R, V et B les valeurs des intensités de chaque canal coloré. La luminosité L est égale à : $$L = R+V+B$$
Pour calculer la luminosité moyenne d’une image, voici l’algorithme:
s = 0
pour chaque ligne:
pour chaque colonne:
p <- couleur du pixel
s = s + (p[0] + p[1] + p[2])/3
luminosite <- s / (ligne*colonne)
Pour chaque pixel, on fait la moyenne de ses 3 couleurs primaires.
On ajoute la valeur à l’accumulateur s. Puis on fait la moyenne des valeurs de s en divisant par le nombre de pixels (ligne*colonne).
Contraste
Les deux images présentées dans le paragraphe précédent, sur la luminosité, sont trop peu contrastées pour en apprécier le contenu.
En effet, l’amplitude de luminosité entre les pixels clairs et les pixels foncés est trop petite. En d’autres termes, les tons sombres et les tons clairs de l’image ont des luminosités qui ont des valeurs trop proches.
Le contraste mesure la différence de luminosité entre les tons clairs et les tons sombre.
Exemple :
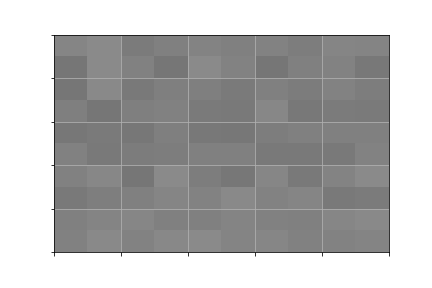
images faible contraste
Soient les fonctions recherche_du_max et recherche_du_min qui retournent la valeur du max ou du min dans une liste python simple.
img est un tableau de valeurs des couleurs en niveau de gris des pixels. Par exemple:
img = [[101,202,210,255,213,...],
[101,202,210,255,213,...],
[...]]
Le programme va parcourir chaque ligne, c’est à dire chaque sous-liste de img.
Si la fonction max_ligne retourne une valeur supérieure à max, c’est qu’une valeur plus grande d’intensité a été trouvée dans cette ligne. On remet à jour la valeur max de l’image avec max = max_ligne, et on passe à la ligne suivante.
(même principe pour min_ligne)
max = 0
min = 255
pour chaque ligne de img:
max_ligne = recherche_du_max(ligne)
min_ligne = recherche_du_min(ligne)
si max_ligne > max: max = max_ligne
si min_ligne < min: min = min_ligne
Qualité des images
La définition D d’une image est définie par un nombre de pixels selon la longueur et la largeur de l’image numérique. C’est une caractéristique propre de l’image.
On l’exprime le plus souvent en donnant les dimensions du plan de pixels, par exemple, une image de définition :
$$1900 \times 1700~pixels$$
La résolution R d’une image numérique correspond à sa densité en points (pixels). On mesure la densité de pixels sur l’écran en pixels par pouce (ppi) et la densité de points sur l’image imprimée en points par pouce (dpi). Ce n’est pas une caractéristique de l’image elle-même, mais de sa restitution par un écran (ou imprimé).
Selon le cas, on calculera la résolution selon l’un des côtés de l’image. Ou bien selon la diagonale de l’iamge.
La résolution peut s’exprimer en pixels par pouce. On peut en déduire la résolution en pixels par cm à l’aide de la relation suivante
entre la Définition D, la Résolution R, et le nombre de cm par pouces (2,54).
$$R(px/cm) = \tfrac{R(px/pouce)}{2,54(cm/pouce)}$$
En effet : 1 pouce vaut 2,54 cm. Un petit calcul montre que R = 72 ppi correspond à 28,3 pixels pour 1 cm.
Exemple : Soit une image de définition 800x533 que l’on imprime sur du papier photo de taille 15x10 (en cm), calculez la résolution de cette image en ppp.
Réponse : On prendra :
Définition : D = 800px et Longueur : L = 15 cm. On cherche R : resolution $$R = \tfrac{D}{L}\times 2,54 = \tfrac{800}{15}\times 2,54 = 135 ppp$$
Agrandissement et perte de qualité: lorsque le nombre de points codés dans l’image est inférieur au nombre de pixels de l’écran, il n’y a pas assez de points. L’agrandissement va déteriorer l’image, car un même point va être placé sur plusieurs pixels côte à côte. C’est ce que l’on appelle la pixelisation de l’image.
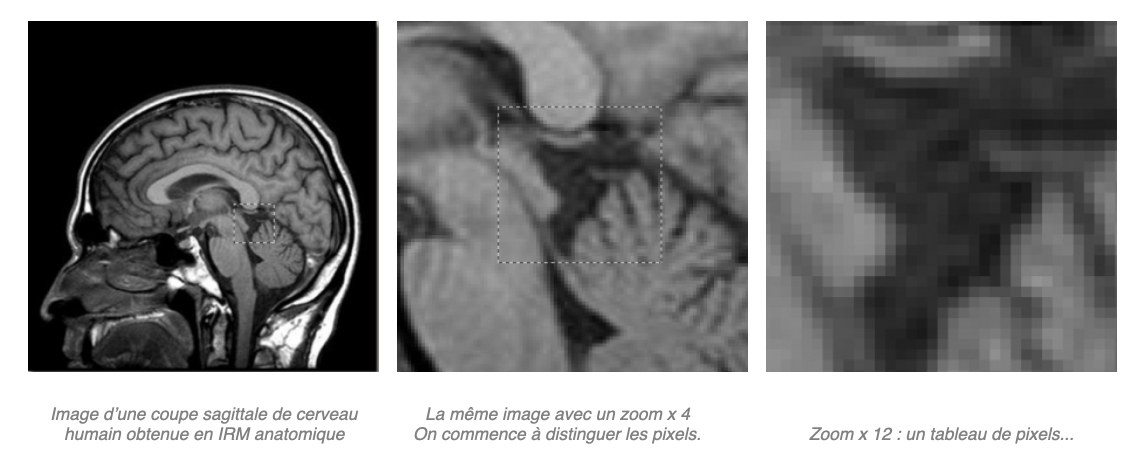
agrandissement jusqu'à pixelisation
La selection d’une partie des points de l’image montre qu’il n’y a plus assez de points avec le zoom x12. On peut afficher une image à partir de cet agrandisement, mais il y a pixelisation. (voir la partie sur la transformation d’une image)
Transformation des images
Poids d’une image avec/sans compression
Image matricielle sans compression
En format brut.
A partir de ce qui a été vu plus haut, le poids d’une image non compressée de définition D et de profondeur de couleur C a un poids P : $$P = D \times C$$
Exemple : D = 1900 pixels * 1700 pixels et C = 3 octets
$$P = 1900 \times 1700 \times 3 = 9,7.10^6 octets = 9,7 Mo$$
En réalité, les images sont compressées. Ce qui permet d’avoir un poids moindre pour leur stockage, leur transfert…
Image matricielle avec compression
La compression d’une image c’est la réduction de la quantité d’informations nécessaires pour décrire l’image. Les idées générales sont :
- De rassembler plusieurs pixels de même couleur, et établir une couleur moyenne des pixels sur une zone donnée.
- supprimer des informations : par exemple en diminuant le nombre de couleurs possibles. On fait une réduction de l’espace des couleurs à celles qui sont les plus fréquentes dans l’image.
Le format PNG est un format d’image bitmap qui utilise la compression sans perte. Le facteur de compression n’est alors pas très élevé. Les données y sont réorganisées pour tenir moins de place. La compression utilise l’algorithme Deflate, basé sur le code de Huffman.
Rappelez vous que le fichier image est constitué de caractères (base 64). C’est donc les occurences de ces caractères dans le fichier qui permet la compression avec l’agorithme Deflate.
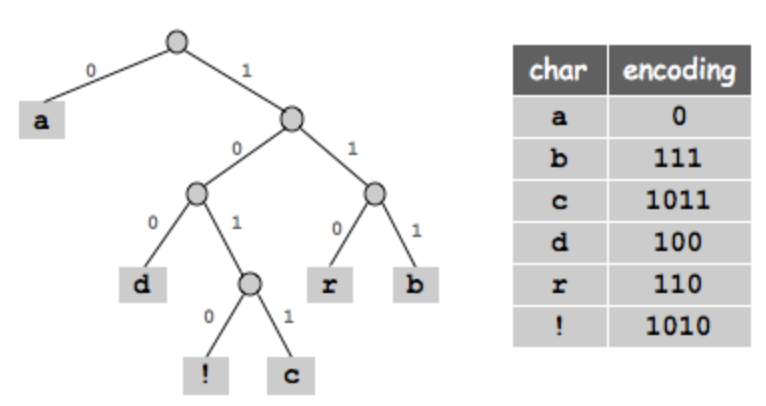
exemple de code de Huffman pour la compression d'un texte
voir explication sur la page de hmalherbe.fr
Le format jpg est un format compressé avec pertes. L’idée est de supprimer la différence de valeur des couleurs pour des pixels contigûs, aux couleurs proches.

La compression réduit la taille du fichier, mais dégrade la qualité de l’image.
image issue du site adobe.com
Traitement d’une image sans modifier sa dimension
On utilise la matrice d’une image source. On créé une matrice d’image cible:
f1 = open('image_source.ppm','r')
M_source = []
for line in f1.readlines()[3:]:
L = line.split()
M_source.append(L)
M_cible = [[0] * len(M_source[0]) for i in range(M_source)]
On parcourt ensuite chaque valeur de pixel de l’image source, on effectue un traitement sur ces valeurs, et on place chacune dans la matrice de l’image cible.

image issue du site de frederic-junier.gitlab.io
Puis on construit l’image cible à partir de sa matrice.
Transformation de la taille d’une image
Certains logiciels permettent de reduire ou agrandir la taille d’une image (resize). Cela modifie le nombre de pixels. Cette transformation se fait en conservant les proportions de l’image (homothétie).
La reduction consiste à choisir certains points de l’image d’origine pour les placer dans celle reduite.
Un agrandissement simple peut se faire en reportant la valeur d’un point sur un carré de points de l’image agrandie:
L’agrandissement peut aussi se faire en faisant une interpolation des valeurs des points (on invente les couleurs manquantes par un calcul de moyenne)
Interpoler: introduire dans une série de valeurs, de nouvelles valeurs intermédiaires.
Merci à zonensi.fr pour le travail sur cette partie du cours.
Lire/écrire dans un fichier
Les algorithmes de compression, d’agrandissement ou de reduction d’image agissent sur D (definition) ou sur C (profondeur de couleur) définis plus haut. Voyons ici la méthode pour lire et écrire dans un fichier image d’extension .ppm. Cela peut se faire à l’aide des fonctions natives de Python. Une autre option est d’utiliser la librairie PIL, comme vu en TP.
Soit le fichier image_source.ppm, dont le contenu est donné ci-dessous (4 premiers pixels)
P3
1000 801
255
87 87 87
84 84 84
81 81 81
80 80 80
On peut manipuler les pixels d’une image à l’aide des instructions natives du langage python.
f1 = open('image_source.ppm','r')
for line in f1.readlines()[3:]:
L = line.split()
print(L)
Sortie:
# affichage des 4 premieres lignes :
['87', '87', '87']
['84', '84', '84']
['81', '81', '81']
['80', '80', '80']
Ce format en listes pour les valeurs des couleurs de pixels est utile pour appliquer un traitement.
Pour recomposer la chaine de caractère à partir de la liste, il faut faire l’opération inverse de line.split(), c’est à dire:
> ' '.join(['87', '87', '87'])
'87 87 87'
On peut rediriger les valeurs vers un nouveau fichier:
f1 = open('image_source.ppm','r')
f2 = open('image_copie.ppm','w')
largeur = 1000
hauteur = 801
f.write('P3'+'\n')
f.write(str(largeur)+' '+str(hauteur)+'\n')
f.write('255'+'\n')
for line in f1.readlines()[3:]:
L = line.split()
# ici: traitement sur les valeurs du pixel
pixel = ' '.join(L)
f2.write(pixel + '\n')
Exercices
Recherche du min/max
Pour parcourir un tableau T à 2 dimensions, il faut 2 boucles imbriquées, la 1ere pour parcourir les lignes, et la 2e pour les colonnes.
Cela donne souvent le script suivant:
script A:
for i in range(len(T)):
# i est le numero de ligne
for j in range(len(T[0])):
# toutes les lignes ont la meme longueur que T[0]
# j est le numero de colonne
... traitement sur T[i][j]
script B:
for line in T:
for elem in line:
... traitement sur elem
- Lequel de ces scripts realise un parcours par indice? Lequel realise un parcours par élément.
- Utiliser l’un de ces scripts pour écrire une fonction
min_max, qui détermine la valeur minimale et la valeur maximale parmi les données de la matrice. - Ecrire une fonction
moyennequi retourne la moyenne des valeurs d’une matrice.
Compréhension de liste
Le script suivant construit une matrice M de zeros:
n = 4
m = 6
M = # a completer (1)
for i in range(n):
for j in range(m):
line.append(0)
# a completer (2)
- Compléter le script
- Quelle est la dimension de cette matrice? Et quelles seraient les dimension de l’image correspondante (largeur/hauteur)?
- Simplifier le script au niveau des lignes 5 et 6, en utilisant l’instruction
[0] * n, qui est équivalent, ici, à[0,0,0,0]. - Ré-ecrire ce même script, en utilisant la compréhension de liste.
Créer une image à partir d’instructions

drapeau suisse
- Ecrire le script qui permet de construire la matrice de ce drapeau suisse, en noir et blanc. La dimension sera de
700*500pixels - Ecrire le script qui construit la matrice du drapeau, mais cette fois, avec la couleur de fond rouge. Chaque élément de la matrice sera un tuple (R,V,B)
Traitement d’une image sans modifier sa dimension
On souhaite transformer une image source en couleur, en une image cible en niveaux de gris. On utilise pour cela la formule de calcul de la Luminence: *(r,g,b sont les intensités des couleurs primaires 0..255)
$$L = 0.299\times r + 0.587\times g + 0.114\times b$$
La valeur calculée pour L sera placée comme niveau de gris dans la matrice cible.
- Ecrire le script de la fonction luminence, qui calcule la valeur de L à partir d’un tuple
(r,g,b) - Placer dans la fonction un test d’assertion sur les valeurs permises pour r,g,b. Ce test, basé sur les données d’entrée, est appelé test de précondition
- Ecrire une fonction
matrice_rgb_to_grisqui créé une matrice de niveaux de gris (valeurs de luminence) à partir d’une matrice couleur.
Agrandissement, reduction
On considère une image source de largeur L et de hauteur H et un entier $k > 0$ :
Un agrandissement de coefficient k de l’image source est une image cible de dimensions $(k\times L,k \times H)$ dont le pixel de coordonnées $(x, y)$ prend la valeur du pixel en $(x//k, y//k)$ dans l’image source.

image issue du site de frederic-junier.gitlab.io
- On considère l’image
3*3de matriceM = [[1,0,1],[0,1,0],[1,1,1]]. Quelle sera la dimension de l’image cible si le coefficientkest égal à 2? - Représenter la matrice
M_cibleavec ses valeurs calculées à partir de celles deM - La fonction
changement_echelleprend 2 paramètres,M, la matrice $(L,H)$ de l’image source, etk, le coefficient. Cette fonction retourne une image calculée sur les valeurs deM, avec une dimension $(k\times L,k \times H)$. Ecrire le script de cette fonction. - Cette fonction, sert-elle aussi pour réaliser une reduction de la taille de l’image source? Donner un exemple.
- Quel défaut aura une image agrandie selon cette méthode?
- Quel sera le poids de l’image reduite d’un facteur k? Exprimer en fonction du poids P de l’image source.
Fiche d’exercices sur les images numeriques: version pdf
Suite du cours
- Enjeux ethiques et societaux de l’image
- Exercices de niveau 1ere NSI: site de frederic-junier
- sujet bac avec corrigé sur code de Huffman: Lien vers la page de hmalherbe.fr
- Compléments sur code de Huffman fiche sur le site madamasterclass.com
