Intelligence artificielle?
L’intelligence artificielle décrit l’ensemble des techniques permettant à des machines de simuler l’intelligence humaine.
Concrêtement, il s’agit de programmer les machines pour qu’elles s’adaptent en fonction des données reçues afin d’effectuer au mieux les tâches qui leur sont assignées.
Dans certains domaines, l’essor de l’intelligence artificielle est lié à l’explosion des données accessibles et des capacités de traitement.
Voir compléments plus théoriques sur l’IA: page du site
Apprentissage automatique
Le machine learning est l’un des domaines de l’intelligence artificielle. Il s’agit:
- d’abord de construire un modèle à partir de données. C’est la phase d’entrainement, ou d’apprentissage.
- Puis d’effectuer des prédictions ou prendre des décisions, sur d’autres données.
En apprentissage automatique, on distingue les algorithmes d’apprentissage:
- supervisés: apprentissage à partir d’exemples déjà etiquettés (classes discretes ou valeurs Y=f(X) connues)
- non supervisées: découverte de la structure de données sans exemples étiquettés.
- par réenforcement: système qui augmente ses performances à partir de ses interactions avec l’environnement. Le système va alors modifier les règles de son modèle au fur et à mesure de ces interactions (plutôt catégorisé comme un apprentissage supervisé).

prediction par un modèle de machine learning avec apprentissage supervisé
Analyse données par regression lineaire
Une étude statistique permet de repérer si certains paramètres sont liés entre eux. Alors, si ces données étaient suffisamment nombreuses et précises, il est possible d’établir des lois mathematiques sur ces données. Une manière de représenter ce lien entre paramètres est, par exemple d’établir une loi de regression linéaire.
Régression linéaire
La régression linéaire est un algorithme qui va trouver une droite qui se rapproche le plus possible d’un ensemble de points. Les points représentent les données d’entraînement (Training Set).
Nuage de points avec Regression Lineaire
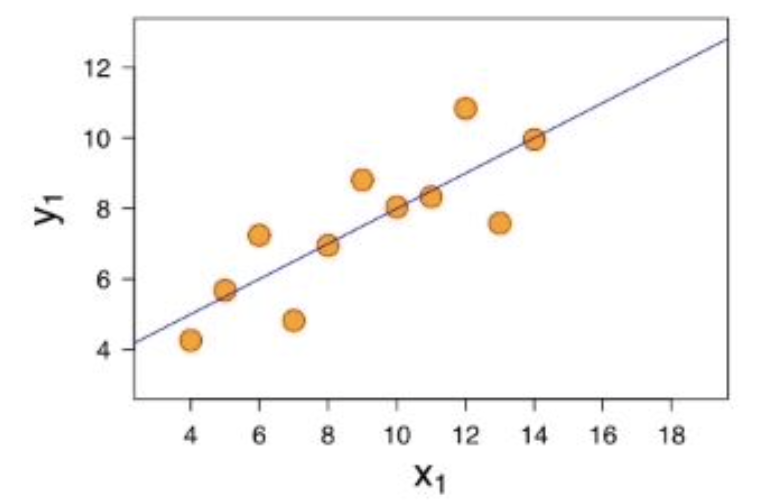
$$Y1 = a \times X1 + b$$
Les écarts entre les points et la courbe du modèle devront être les plus petits possibles.
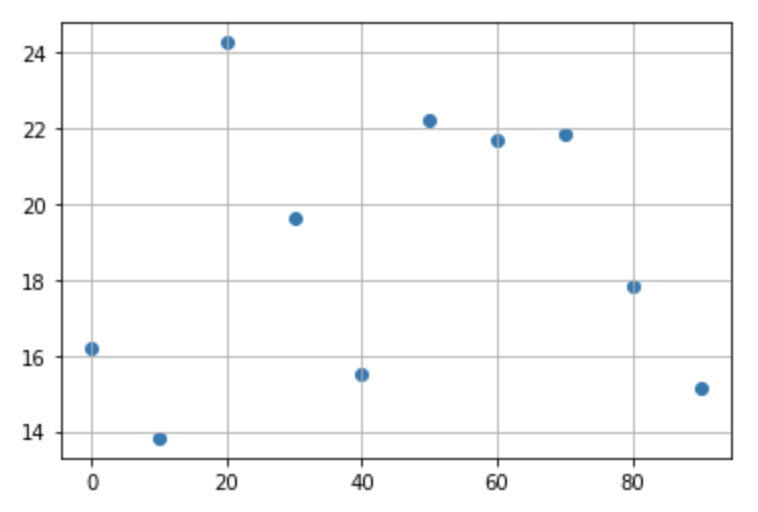
Regression linéaire impossible
Modèle prédictif
Un modèle prédictif ne peut être établi qu’à partir d’une étude prealable de données.
Pour de nouvelles données, on peut alors, grâce à un modèle, prédire le comportement futur du nouvel objet. Faire une estimation, calculer une valeur. A condition que celui-ci fasse partie de la même famille d’objets que ceux qui ont permis d’établir le modèle.

nouvelle donnée d'absisse X1 => Y1 determiné grace au modèle (regression)
Exemple
Cet exemple est issu du Blog mrmint.fr.
Supposons que vous soyez le chef de direction d’une franchise de camions ambulants (Food Trucks). Vous envisagez différentes villes pour ouvrir un nouveau point de vente. La chaîne a déjà des camions dans différentes villes et vous avez des données pour les bénéfices et les populations des villes.
Vous devrez utiliser ces données pour vous aider à choisir la ville pour y ouvrir un nouveau point de vente.
Ce problème est de type apprentissage supervisé modélisable par un algorithme de régression linéaire. Il est de type supervisé car pour chaque ville ayant un certain nombre de population (variable prédictive X), on a le gain effectué dans cette dernière (la variable qu’on cherche à prédire : Y).
Notebook
Vous utiliserez le notebook en ligne sur Jupyterlite
Algorithme des K proches voisins Knn
Principe
Il s’agit d’un algorithme d’apprentissage supervisé, initialisé par des exemples connus. Pour cela, on part d’un jeu de données existant dont on connait les classes.
L’algorithme KNN (k-nearest neightbors) permet de déterminer à quelle classe appartient un nouvel élément.
Exemple: Les joueurs de NBA
On cherche une correspondance entre les caractéristiques physiques d’un joueur de basket et son poste sur le terrain.
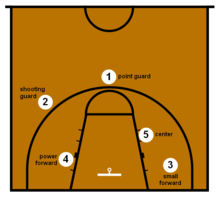
Pour simplifier, on considerera que les postes sont au nombre de trois :
- le joueur Centre, noté ‘C’ (position 5 sur le schéma)
- Le joueur Ailier, noté ‘F’ (positions 3 et 4 sur le schéma)
- Le joueur arrière ou meneur de jeu, noté ‘G’ (positions 1 et 2 sur le schéma)
Les données sont issues de la page : nba.com
La ligue de basket americaine contient environ 400 joueurs professionnels. La plupart de nationalité américaine. On dispose d’un extrait de ce fichier (voir dans le dossier datas), constitué de moins de 100 joueurs, classés par ordre alphabetique.
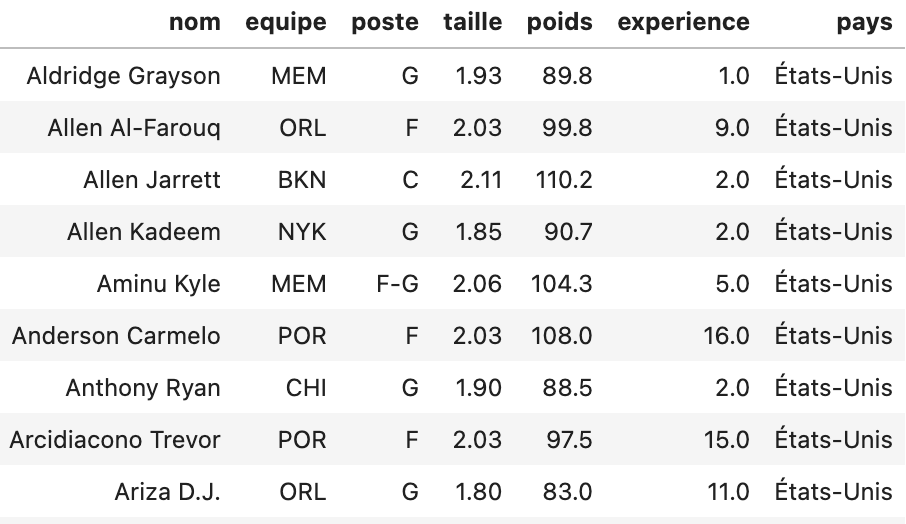
extrait du tableau des joueurs NBA en 2020
Apprentissage supervisé
Chaque joueur de basket occupe un poste particulier sur le terrain:
poste occupé sur le terrain
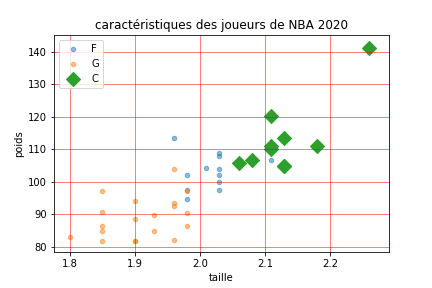
les joueurs
Prédiction
On peut alors prévoir le poste d’un nouveau joueur. Pour cela on observe ses k plus proches voisins, et on en déduit quel poste corresspnd à son physique, à partir de la classe majoritairement représentée.
Le joueur semble être à la limite des classes
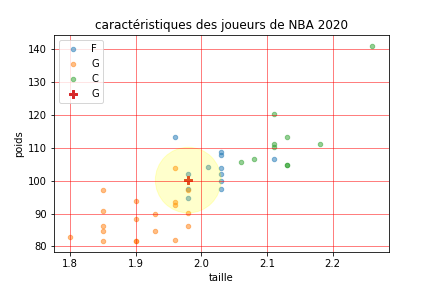
- on ajoute une nouvelle colonne calculée: Pour le joueur inconnu, on calcule la distance avec chaque élément classé dans le tableau .
- on trie le tableau selon la distance.
- on observe la classe majoritaire pour les k premiers éléments classés de la liste triée. La valeur de k doit être représentative. On prendra la plupart du temps $k = \sqrt N$
Travaux pratiques
- Predire le poste d’un joueur de NBA: Lien vers le TP
- Activité sur feuille: lien vers pdf
Liens
documents utilisés pour la redaction de la page
- s’initier au machine learning https://openclassrooms.com/fr/courses/4011851-initiez-vous-au-machine-learning/4020611-identifiez-les-differents-types-dapprentissage-automatiques
- Méthodes de fouilles : http://www.lsis.org/espinasseb/Supports/DWDM/10-MethodesFouille-4p.pdf
- La règlementation sur les algorithmes d’IA: Faut-il interdire ces algorithmes dans certains secteurs: rapport du CNIL: garder la main
- Comment rendre les algorithmes responsables? Le Monde.fr internetactu
Approfondissement
-
Différence entre Intelligence Artificielle, Machine Learning et Deep Learning : http://penseeartificielle.fr/difference-intelligence-artificielle-machine-learning-deep-learning/
-
Inférence bayesienne : Les probabilités conditionnelles (Bayes) - le blog de David Louapre : https://sciencetonnante.wordpress.com/2012/10/08/les-probabilites-conditionnelles-bayes-level-1/
-
theorie sur le machine learning : https://makina-corpus.com/blog/metier/2017/initiation-au-machine-learning-avec-python-theorie
-
machine learning : utiliser SciKit https://makina-corpus.com/blog/metier/2017/initiation-au-machine-learning-avec-python-pratique
-
apprentissage statistique avec scikit-learn : https://www.math.univ-toulouse.fr/~besse/Wikistat/pdf/st-tutor3-python-scikit.pdf
