Le protocole HTTP

HTTP - chaine Cookie connecté
Des requêtes HTTP jusqu’à la page Web
HTTP est un protocole de la couche Application selon le modèle de communication entre machines OSI (développé dans ce cours).
C’est le protocole qui permet de récupérer des ressources telles que des documents HTML. Il est à la base de tout échange de données sur le Web. C’est un protocole de type client-serveur, ce qui signifie que les requêtes sont initiées par le destinataire (qui est généralement un navigateur web).
Le protocole HTTP est un protocole synchrone: pour chacune des tâches, il faut attendre la réponse avant d’exploiter la ressource chargée.
Un document complet est construit à partir de différents sous-documents qui sont récupérés, par exemple du texte, des descriptions de mise en page, des images, des vidéos, des scripts et bien plus.
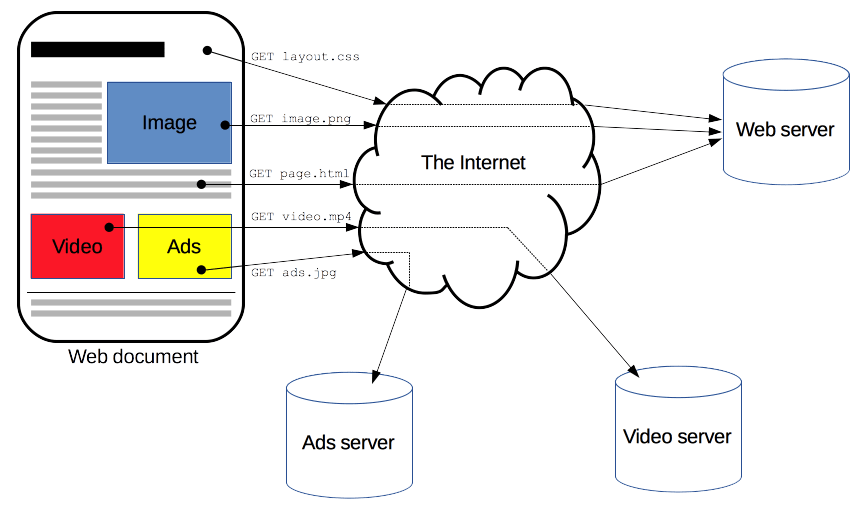
requêtes pour la construction d'une page web. Source: MDN Web Docs
Le navigateur web assemble alors ces ressources pour présenter un document complet à l’utilisateur : c’est la page web.
Pour obtenir ces fragments de page, le navigateur web envoie des messages qui sont appelés des requêtes et les messages renvoyés par le serveur sont appelés réponses.
Entre une requête et la réponse se trouvent de nombreuses entités qu’on désignera de façon générique sous le terme proxies. Celles-ci exécutent différentes opérations et agissent comme passerelles ou comme caches par exemple.
En réalité, il y a plus d’un ordinateur entre un navigateur et le serveur qui traite la requête : il y a les routeurs, les modems et bien plus. Grâce à la construction en couche du Web, ces intermédiaires sont cachés dans les couches réseau et transport. HTTP, lui, est bâti sur la couche applicative.
Pour plus de détails, voir la page sur MDN Web Docs.
naviguer sur le web
Une page web est un document hypertexte. Cela signifie que certaines parties sont des liens hypertextes qui peuvent être activés (généralement avec un clic de souris) afin de récupérer une nouvelle page web, permettant à l’utilisateur de naviguer sur le Web.
Encore une fois, c’est le navigateur qui traduit ces instructions en requêtes HTTP.
Plus de détails: voir page du site IONOS
Ce protocole HTTP contrôle la façon dont le client formule ses demandes et la façon dont le serveur y répond, et connaît différentes méthodes de requête: GET, POST, HEAD, OPTIONS, TRACE, ou autres méthodes spécifiques.
Méthodes HTTP
HTTP est un protocole de la couche Application pour lequel le client et le serveur communiquent grâce aux en-têtes.
- Pour la requête, c’est dans l’en-tête que la demande est formulée.
- Pour la reponse, le serveur ajoute un en-tête, utile pour le protocole.
GET
c’est la méthode HTTP qui est la plus utilisée pour demander une ressource, par exemple un fichier HTML, au serveur Web. Dans le navigateur, on fait cette demande grâce à une URL (uniform ressource locator)
Comprendre les URL et leur structure (MDN)
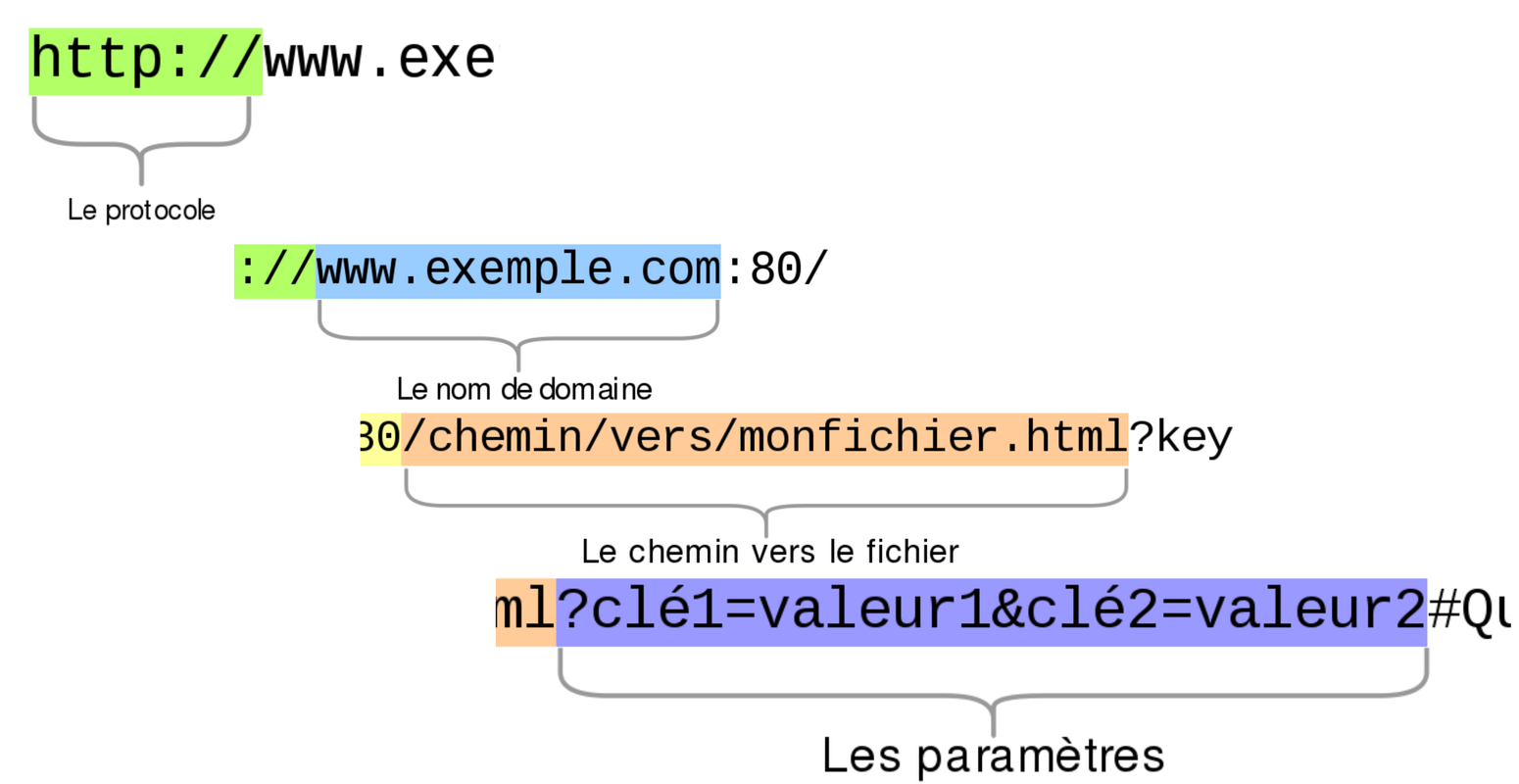
Comprendre les URL et leur structure
Si l’on saisit l’URL www.exemple.com/test.html dans la barre d’adresse du navigateur, celui-ci se connecte au serveur Web www.exemple.com et lui envoie la requête GET qui contiendra:
- la méthode de communication client-serveur: ici
GET - le chemin vers la ressource:
/test.html
GET /test.html
Le serveur renvoie alors le fichier test.html.
Déroulé d’une requête HTTP par la méthode GET
Des paramètres d’URL qui peuvent être ajoutés à l’URL s’appelent chaine query, ou chaine de requête.
Une URL valide est alors construite de la manière suivante:
# nom de domaine symbolique
http://nom du domaine.org/chemin_vers_la_ressource?chaine query
La requête GET contient alors des informations supplémentaires que le serveur Web doit traiter.
Les règles de syntaxe employées:
- La chaîne de requête est introduite par un « ? » (point d’interrogation).
- Chaque paramètre est nommé, il se compose donc d’un nom et d’une valeur : « Nom=Valeur ».
- Si plusieurs paramètres doivent être inclus, ils sont reliés par un « & ».

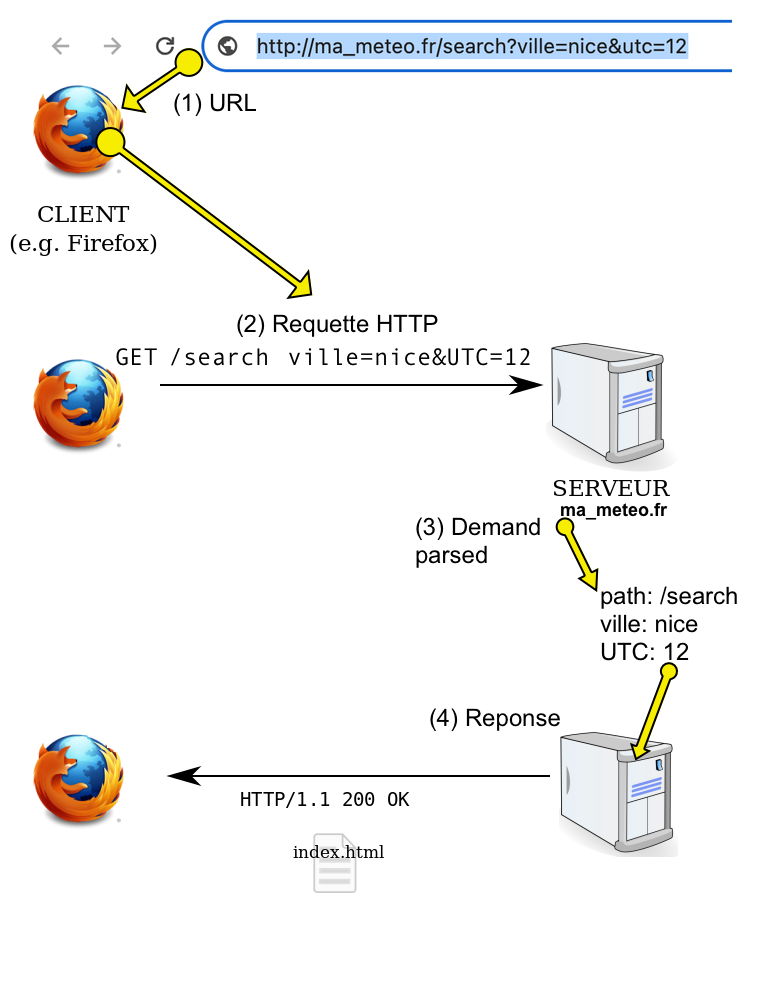
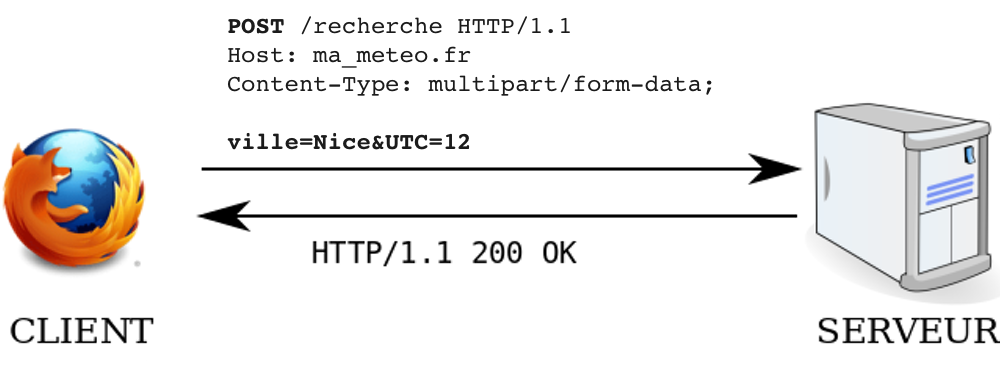
Par exemple, sur un site de météo, Nice est saisi comme ville et 12 comme heure UTC. L’URL saisie dans le navigateur pourrait être:
http://ma_meteo.fr/search?ville=Nice&UTC=12
Il se produit alors plusieurs étapes avant l’affichage de la page par le navigateur:
- (1): saisie de l’URL dans la barre d’adresse (ou activation d’un lien depuis la page web)
le navigateur établit une connexion TCP avec le serveur du site ma_meteo.fr puis lui envoie la requête HTTP suivante:
GET /search?ville=Nice&UTC=12
- (2): émission de la requêtte HTTP dans un format normalisé (ex. HTTP/1.1)
- (3): la requête est parsée
[voir ci-dessous]et interprétée par le serveur - (4): reponse du serveur avec un en-tête HTTP ainsi que le script html de la page demandée.
Definition du terme PARSE:
“Parser” signifie analyser et convertir un script en un format interne que l’environnement d’exécution peut interpréter. Il s’agit d’une analyse syntaxique. Un paragraphe de la page sur les variables en python est consacré à la manipulation d’une chaine de caractères, ainsi qu’à la méthode parse en Python.
inconvenients de la méthode GET
La méthode GET est la plus utilisée pour obtenir les ressources qui construisent la page Web dans le navigateur.
Cette méthode présente des limites lorsque cette page doit être personnalisée:
Avec la méthode GET, les données à envoyer au serveur sont aussi écrites dans l’URL.
Cela présente un avantage: Les paramètres de l’URL peuvent être enregistrés avec l’adresse du site Web. (utile pour un marque page, historique de navigation, enregistrer des pages Web contenant certains paramètres de filtrage et de tri, meteo avec conservation de la localisation…).
Le principal inconvénient de la méthode GET est l’absence de protection des données. Un deuxième inconvénient est sa capacité limitée : suivant le serveur Web et le navigateur, l’URL ne peut pas contenir plus de 2 000 caractères environ.
La méthode POST
Cette méthode n’écrit pas les paramètres de l’URL, mais les ajoute à l’en-tête HTTP (HTTP header)
Revenons sur l’exemple de la page meteo. Voici un aperçu des interactions possibles entre l’utilisateur et la page. Celle-ci pourrait présenter:
- un champs de texte à remplir (Ville)
- un menu déroulant (heure)
Comparatif GET POST
| GET | POST | |
|---|---|---|
| Visibilité | Visible pour l’utilisateur dans le champ d’adresse | Invisible pour l’utilisateur |
| Marque-page et historique de navigation | Les paramètres de l’URL sont stockés en même temps que l’URL. | L’URL est enregistrée sans paramètres URL. |
| Cache et fichier log du serveur | Les paramètres de l’URL sont stockés sans chiffrement | Les paramètres de l’URL ne sont pas enregistrés automatiquement. |
| Comportement lors de l’actualisation du navigateur / Bouton « précédent » | Les paramètres de l’URL ne sont pas envoyés à nouveau. | Le navigateur avertit que les données du formulaire doivent être renvoyées. |
| Type de données | Caractères ASCII uniquement. | Caractères ASCII mais également données binaires. |
| Longueur des données | Limitée - longueur maximale de l’URL à 2 048 caractères. | Illimitée. |
- GET pour les paramètres d’un site Web (filtres, tri, saisies de recherche, etc.).
- POST pour la transmission des informations, des fichiers, et des données de l’utilisateur.
Autres méthodes HTTP
La méthode HEAD
Utilisée pour interroger l’en-tête de la réponse, sans que le fichier ne vous soit envoyé immédiatement. C’est utile, par exemple, si des fichiers volumineux doivent être transférés : grâce à la requête HEAD, le client peut d’abord être informé de la taille du fichier et seulement ensuite décider s’il veut recevoir le fichier.
OPTIONS
Avec la méthode OPTIONS, le client peut demander quelles méthodes le serveur supporte pour le fichier en question. Ces méthodes autorisées sont contenues dans le champs d’en-tête “allow”.
TRACE
La méthode TRACE peut être utilisée pour tracer le chemin qu’une requête HTTP emprunte jusqu’au serveur puis jusqu’au client. Vous pouvez utiliser la commande tracert de Windows pour tracer vous-même cet itinéraire.
tracert www.exemple.com
HTTP header
HTTP header Côté client
Chaque requête HTTP formulée par le navigateur contient:
- une premiere ligne constituée de: METHODE suivie du PATH (chemin vers la ressource) suivi de la version HTTP. Exemple: `GET /index.php HTTP/1.1
- Puis vient le HTTP header.
Pour le client, voici les principales informations contenues dans le http header:
| Champ d’en-tête | Signification | Exemple |
|---|---|---|
| Accept | Les types de contenu que le client peut traiter ; si le champ est vide, il s’agit de tous les types de contenu. | Accept: text/html, application/xml |
| Accept-Charset | Quels jeux de caractères le client peut afficher. | Accept-Charset: utf-8 |
| Cookie | Cookie stocké pour ce serveur | Cookie: $Version=1; Content=23 |
| Content-Length | Longueur en octets | Content-Length: 212 |
| Content-Type | Type MIME: text/plain pour les fichiers texte, application/.. pour le reste | Content-Type: application/x_222-form-urlencoded |
| Date | Date et heure de la demande | Date: Mon, 9 March 2020 09:02:22 GMT |
| Host | Nom de domaine du serveur | Host: exemple.fr |
| Referrer | URL de la ressource à partir de laquelle la demande est faite (c’est-à-dire à partir de laquelle le lien a été créé) | Referrer: https://exemple.fr/index.html |
| User-Agent | navigateur du client | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36 |
HTTP header Côté serveur
Chaque reponse HTTP retournée par le serveur contient:
- une premiere ligne constituée:
- de la version HTTP
- du code statut (200, 301, 404, …)
- du message de statut (OK, …)
- puis les différents champs de l’en-tête.
- et enfin le contenu html ou autre.
Sur l’exemple suivant, on voit par exemple, sur la 1ere ligne:
- HTTP/1.1 est la version valide du protocole HTTP.
- 200 OK est le code de statut. Il indique que le serveur a reçu, compris et accepté la demande.
Le serveur renvoie cet en-tête avec la page HTML
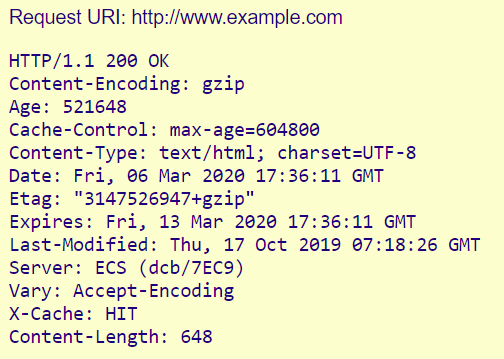
- Content-Encoding et Content-Type fournissent des informations sur le type de fichier.
- Age, Cache-Control, Expires, Vary et X-Cache font référence à la mise en cache du fichier.
- Etag et Last-Modified sont utilisés pour le contrôle de la version du fichier livré.
- Le terme « server » désigne le logiciel du serveur Web.
- Content-Length est la taille du fichier en octets.
Classes de statut HTTP
erreur 404: page internet introuvable
- Classe 1xx, codes d’information : si le code commence par 1, le serveur indique au client que la requête actuelle est en en train de se faire. Cette classe regroupe des codes en cours de traitement et d’envoi.
- Classe 2xx, codes de succès : un code qui commence par 2 indique que la requête a abouti. Elle a été reçue par le client, comprise et acceptée. En conséquence, les codes 2xx du serveur sont envoyés en même temps que les informations des pages Web désirées. En général, l’utilisateur ne prend en compte que la page Web qu’il a chargé.
- Classe 3xx, codes de redirection : un code 3xx indique que la requête a été reçue par le serveur. Cependant, le client doit encore provoquer une action complémentaire. Par exemple, le code HTTP 301 signifie changement d’adresse définitif : les informations demandées par le client ne se trouvent plus à l’adresse indiquée car celle-ci a définitivement changée. Le navigateur Internet peut aussitôt rediriger l’utilisateur à la nouvelle adresse.
- Classe 4xx, erreurs du client : le code 4xx renvoie à une erreur commise par le client. Le serveur a reçu la requête mais ne peut pas l’exécuter. La réponse 404 signifie par exemple que la page Internet est introuvable.. En général, il s’agit d’une syntaxe erronée. En général, l’utilisateur est automatiquement dirigé vers une page HTML.
- Classe 5xx, erreurs du serveur : Le code 5xx fait référence à une erreur commise par le serveur. Ces informations indiquent que la requête en question est complètement ou provisoirement impossible. Une page d’erreur HTML est également présentée.
HTTP: sécurité et confidentialité
Sécurité
La sécurité d’un protocole vise à ce que les communications ne soient pas exploitables pour quelqu’un qui intercepte le message.
Le protocole HTTP possède une version sécurisée des échanges: il s’agit de HTTPS.
confidentialité: HTTP, un protocole sans ETAT
Pour une communication client-serveur: Un état est conservé entre 2 requêtes si l’utilisateur, le client, s’est identifié.
Protocole sans état
Un protocole sans état (en anglais stateless protocol) est un protocole de communication qui n’enregistre pas l’état d’une session de communication entre deux requêtes successives. La communication est formée de paires requête-réponse indépendantes et chaque paire requête-réponse est traitée comme une transaction indépendante, sans lien avec les requêtes précédentes ou suivantes.
Le protocole HTTP est donc un protocole synchrone, et sans état.
Des couches de protocoles avec et sans état:
Dans les différentes couches de protocoles de communication: le protocole HTTP (sans état) s’appuie sur le protocole TCP, un protocole avec état, qui s’appuie à son tour sur le protocole IP, un autre protocole sans état.
Cookies
1. A quoi servent les cookies? voir MDN: HTTP cookies
Les cookies permettent de conserver de l’information en passant par le procotole HTTP qui est lui “sans état”.
Les cookies, ce sont des données qu’un serveur envoie au navigateur web de l’utilisateur. Le navigateur peut alors le stocker localement, puis le renvoyer à la prochaine requête vers le même serveur. Typiquement, cette méthode est utilisée par le serveur pour déterminer si deux requêtes proviennent du même navigateur.
Cela permet:
-
Gestion des sessions Logins, panier d’achat, score d’un jeu, ou tout autre chose dont le serveur doit se souvenir.
Par exemple, garder un utilisateur connecté. -
Personnalisation Préférences utilisateur, thèmes, et autres paramètres.
-
Suivi Enregistrement et analyse du comportement utilisateur.
2. Protection des données
contrôle des cookies par l'utilisateur
Les cookies étaient auparavant utilisés pour le stockage côté client. Mais aujourd’hui, la tendance est plutôt d’envoyér ces données avec chaque requête. Cela a pour conséquence de partager ses données pour l’internaute. Son surf n’est plus complètement anonyme.
En application de la directive ePrivacy, les internautes doivent être informés et donner leur consentement préalablement au dépôt et à la lecture de certains traceurs
Les cookies ont un domaine qui leur est associé. Si ce domaine est le même que la page sur laquelle vous êtes, on parle de cookie interne (first-party cookie). Si le domaine est différent, on parle de cookie tiers (third-party cookie).
Pour plus de détails, voir la page: Quel est le cadre juridique applicable?
HTTPS
HTTPS : les en-têtes sont-elles chiffrées ?
Oui, avec HTTPS, les en-têtes HTTP sont bien chiffrées — et c’est un point souvent mal compris! Ce qu’il se passe réellement:
- HTTPS = HTTP + TLS (Transport Layer Security)
- Le chiffrement TLS s’applique à tout le contenu HTTP, c’est-à-dire :
✅ Les en-têtes (headers) — Host, Cookie, Authorization, User-Agent…
✅ Le corps de la requête (body)
✅ Les en-têtes de réponse du serveur — Set-Cookie, Content-Type…
✅ Le corps de la réponse
Ce qui reste visible (non chiffré) Même en HTTPS, quelques informations transitent en clair :
| Élément | Visible ? Pourquoi | |
|---|---|---|
| Adresse IP du serveur | ✅ Oui | Nécessaire pour le routage réseau |
| Port (443) | ✅ Oui | Idem |
| Nom de domaine (SNI) | ⚠️ Souvent oui | Échangé pendant la négociation TLS pour choisir le bon certificat |
| URL complète / chemin | ❌ Non | Chiffré |
| En-têtes HTTP | ❌ Non | Chiffrés |
SNI (Server Name Indication) : lors de la poignée de main TLS (handshake), le client indique le nom de domaine cible. Cette information est traditionnellement en clair, bien que la technologie ECH (Encrypted Client Hello) commence à chiffrer cela aussi.
On peut souvent deviner le domaine (via le SNI ou l’IP), mais pas la page précise visitée (l’URL complète, les cookies, les paramètres…).
Schéma simplifié
[Couche réseau] IP source / IP destination → visible
[Couche TLS] Handshake TLS (certificat) → partiellement visible
[Couche HTTP] En-têtes + Corps → chiffré ✅
Travaux Pratiques:
Formulaire et protocoles de transmission
La vulnérabilité des services d’authentification web correspond aux faiblesses des protocoles d’authentification du web.
On traitera de ces problèmes avec le TP suivant: Lien
le moniteur réseau
TP inspiré de la page MDN Mozilla
Le moniteur réseau du navigateur affiche des informations sur les requêtes effectuées (par exemple, au chargement d’une page).
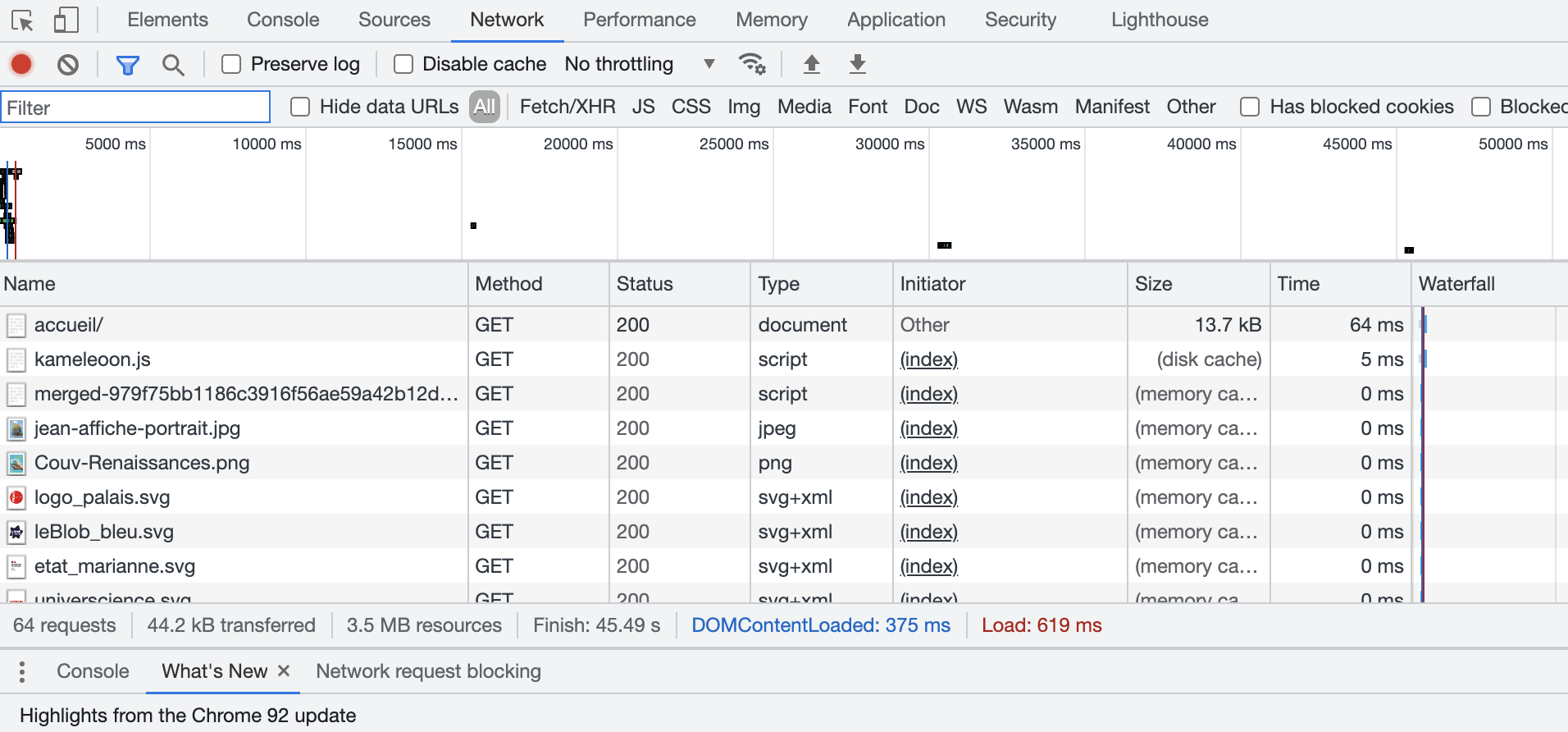
Outils de developpement sous Chrome
Faire une recherche sur un moteur de recherche pour trouver l’URL de la page d’accueil du site cité des sciences.
1. Lorsque vous lancez un recherche sur un moteur de recherche, celui-ci utilise t-il une méthode GET ou POST? Justifiez. Quel est l’intérêt d’utiliser cette méthode?
Aller sur la page d’accueil du site de: cité des sciences.
2. Ouvrir le moniteur réseau du navigateur.
3. Après avoir rechargé la page de cité des sciences, quel est le nombre de requêtes?
4. Ce nombre évolue t-il alors que vous laissez la page ouverte, sans aucune action de votre part?
5. Est-ce que toutes les requêtes sont de type GET?
6. Cliquer sur la première ressource téléchargée, accueil/. Vous obtenez alors le détail de la ressource.
- Quelle est la différence entre les informations transmises par le Headers et celles transmises par le Reponse (ou Response)?
- Pour l’onglet Headers: S’agit-il du HTTP header émis par le client ou bien celui serveur? Justifier.
- Reconnaitre et interpréter certains champs de l’en-tête.
7. Aller sur l’onglet Cookies pour cette première ressource. Que remarquez vous?
- Y-a-t-il des ressources qui ont un code statut différent de 200? Quels sont-ils et que signifient-ils?
- Quel est le nom de domaine qui revient le plus souvent pour ces requêtes, dont le statut est différent de 200?
- Pour l’une de ces ressources, on observe en détail l’extension de l’URL que l’on appelle Query String (chaine Query). Celle-ci est écrite en Base 64. Elle est constituée de la série de caractères suivante:
c2l0ZUNvZGU9ZGFjcGJybDR0byZ2aXNpdG9yQ29kZT1mMnBvbGJucXRhNTU5b3YwJnN0YXJ0T2ZWaXNpdD1mYWxzZSZzY3JpcHRWZXJzaW9uPTIwMTkwMTE1Jm5vbmNlPThGRjcyMTVBRjMyOUM4MEEmZXZlbnRUeXBlPWFjdGl2aXR5JnRpbWU9MTYzNTc3NDY4NDMzNyZhY3RpdmU9ZmFsc2UmbnVtYmVyQ2xpY2tzPTAmdGFiQ291bnQ9MA==
Utiliser un décodeur en base 64, comme par exemple base64.guru et afficher le texte decodé.
8. De quoi peut-il s’agir?
Pour l’outil de developpement du navigateur, on pourra s’aider de la page MDN Web Docs: Détails des requêtes réseau
Liens
- voir aussi: MDN Flux HTTP
- Vol de cookies et détournement de session: kaspersky.fr
…Dans le cas du protocole HTTP, les fichiers cookies sont transmis en texte clair dans les en-têtes des requêtes HTTP, ce qui signifie qu’ils ne sont pas chiffrés. Un acteur malveillant (reseau wifi public) peut alors facilement intercepter le trafic entre vous et le site Internet sur lequel vous vous trouvez, et en extraire les cookies…
- Peut-on utiliser cette technique pour bypasser le proxy du lycée? video youtube de 2015 => Non à cause des hebergements mutualisés, et de l’identification par l’en-tête host, necessaire pour la phase de présentation (https)
